Experiências com CI/CD e DevOps
Praticando DevOps com papel e caneta
AVISO: Apesar da falta relativa de detalhes, esse artigo acabou tão extenso que fui obrigado a incluir uma tabela de conteúdo. Espero que não seja uma leitura cansativa, e que quem estiver lendo consiga pular para um tópico de seu interesse.
O propósito desta postagem é dar ao leitor um resumo de como foi, para mim, se acostumar com e implementar soluções de integração contínua (CI) e deployment contínuo (CD) em meus projetos pessoais. Foi e ainda está sendo como uma rodovia esburacada, mas é mais gratificante do que achei que seria quando comecei.
Minha atitude para com serviços, programas e plataformas de CI/CD era de que “não são pra mim”, e algo de que só projetos grandes ou empresas, liderados por uma força-tarefa altamente qualificada, precisariam e tirariam proveito.
Tal posição com certeza mudou quando, trabalhando diretamente com o ciclo de desenvolvimento de software e melhorando-o, tomei consciência do seu valor e sentido. Agora eu sinto grande vontade de trazer testes automatizados, revisões de código, pull requests constantes, e deployment automático para todos os meus projetos pessoais. É um ótimo jeito de definir e garantir um padrão de qualidade.
Engatinhando: Git hooks & GNU Make
A primeira esteira de desenvolvimento de software — se é que pode ser chamada
assim — que criei foi uma combinação de Git, Bash, e GNU Make, com este
grudando programas como Hugo e rsync. Seu propósito era automatizar o
deployment do meu site pessoal.
Git foi usado para versionamento do código-fonte, GNU Make foi usado para
simplificar os processos de build e deployment, Hugo foi usado para transformar
Markdown + templates em HTML e CSS, e rsync foi usado para copiar as páginas
geradas para a raíz do servidor Web — /var/www.
Para transformar o git push no único comando necessário para iniciar um build
e fazer deploy do novo conteúdo, um hook post-receive foi criado
num repositório “bare” hospedado na VPS que servia o website. O hook era nada
mais do que um script shell, mais ou menos assim:
cd /path/to/the/worktree # vá para um clone do repo
git fetch origin # obtenha as novas commits
git reset --hard origin/master # sincroniza com master
make && make deploy # faz o build e o deploy das páginas
Contanto que as permissões estivessem corretas e as dependências instaladas,
tudo que eu precisava fazer para atualizar as páginas do seu site era editar os
arquivos localmente, criar novas commits, e enviá-las para o remote. Se algum
erro ocorresse, eu conseguiria vê-lo na saída do git push, pois este mostra a
saída dos hooks enquanto são executados.
Por que não houve Integração Contínua
Mesmo com toda minha felicidade na época com minha nova descoberta (hooks do Git) e minha configuração, em retrospecto não dá para dizer que havia CI. Antes de listar minhas razões, a seguir está a definição de Integração Contínua dada pela Atlassian:
Integração Contínua (CI) é a prática de automatizar a integração de mudanças no código feita por múltiplos contribuidores em um só projeto de software. É uma boa prática primária de DevOps, permitindo a desenvolvedores frequentemente integrar mudanças a um repositório central, onde builds e testes são então executados.
Apesar dessa definição, eu pessoalmente acredito que pode-se atingir CI mesmo quando há somente um contribuidor, mas se você discorda de mim, adicione esse fato à seguinte lista de razões pelas quais não houve integração contínua no projeto em questão.
Razão #1: Há somente um branch — master —, portanto mudanças sendo
testadas já foram integradas.
O propósito de CI é testar e revisar mudanças antes de integrá-las ao branch de destino. Suítes como GitHub, GitLab, Bitbucket, entre outras são extremamente úteis: elas materializam a ideia de proposta de mudança em pull (ou merge) requests. Estas requests podem ser negadas, aceitas, revisadas, etc., e ainda mais legal é o fato de que quando são criadas ou modificadas, a suíte pode nos notificar programaticamente por meio de webhooks, e até tratar dos eventos nativamente.
No meu caso, não haviam pull requests: commits eram adicionadas à master e
empurradas diretamente upstream, sem mais nem menos.
Razão #2: O único teste feito é deployment.
Não há teste automatizado de nenhum tipo, nem mesmo para ver se as páginas ainda seriam geradas. Consigo até lembrar de momentos em que quebrei a geração das páginas enquanto testava as capacidades de template do Hugo — a versão instalada na minha máquina era diferente da instalada no servidor.
A falta de um ambiente facilmente reproduzido para testes (e obviamente os testes em si) significava que todo deployment feito arriscava quebrar a “produção”.
Razão #3: Mudanças não passam por nenhum processo de revisão.
Para várias pessoas, revisão de código não está necessariamente dentro do escopo de integração contínua, mas na minha humilde opinião, é central para esta. Se CI tem o intuito de controlar ou garantir um grau de qualidade antes de mudanças entrarem em branches estáveis, revisões estão perfeitamente alinhadas com ela, e ficam no caminho da integração.
Eu disse antes que acredito que CI pode ser atingida mesmo quando há somente um contribuidor, então por que levanto esse ponto? A razão é que eu não revisava minhas próprias mudanças. Eu as testava localmente, claro, mas não as revisava com imparcialidade depois do desenvolvimento. A falta de qualquer processo de revisão, ao meu ver, desclassifica esta esteira de receber o apelido de integração contínua.
Por que houve Deployment Contínuo (talvez)
Se você espremer bem os olhos, ou for permissivo no acoplamento entre CI e CD, o setup com Git & Make tinha, sim, deployment contínuo. Mais uma vez, começamos com uma definição. Dessa vez, ela vem do TechTarget:
Deployment Contínuo (CD) é uma estratégia de lançamento de software onde toda commit que passa pela fase de teste automatizado é automaticamente lançada no ambiente de produção, fazendo mudanças visíveis aos seus usuários.
Commits que chegavam à master, usada para produção no nosso caso, chegariam
automaticamente ao ambiente de produção — a versão do site servida pelo
servidor. Nesse sentido, isso foi um exemplo de deployment contínuo, mas se não
há CI, pode haver CD? É necessária a presença dessa “fase de teste automático”
para que o deployment seja contínuo?
Eu diria que não. CI e CD são ambos premissas fundamentais da cultura DevOps, mas a implantação dos dois costuma ser feita separadamente. Fossem eles genuinamente inseparáveis, provavelmente teríamos uma expressão só a designar a “unidade” composta por ambos.
O caminho para CI/CD propriamente dito
Meus olhos se abriram para CI/CD quando comecei a trabalhar. Até então, mal sabia o que significavam, se é que havia realmente ouvido falar dos dois. A mim, CI era a segunda parte de Travis CI, uma ferramenta que rodava builds no repositório do XMonad de forma automática, e CD era um formato de mídia ótica.
Começo a trabalhar e quase que de imediato, me deparo com o Jenkins. Ele me foi apresentado como a ferramenta de escolha para a maioria dos desenvolvedores para criar esteiras de CI/CD, e dá para ver por quê. No entanto, o sentimento que o Jenkins passa, quanto mais experiência com ele você adquire, é de um programa equivalente a um pano de prato feito de vários remendos e que consome mais recursos do que deve ser necessário.
Inexperiente e com os olhos brilhando, refletindo uma nova admiração pela
construção de esteiras de desenvolvimento, busquei escrever algumas
Jenkinsfiles para automatizar processos como alterações no firmware do meu
eReader.
Criados e configurados repositórios aqui e ali, lendo a documentação enquanto pensava “rapaz, que trabalheira isso deu, mas vai valer a pena”, minha atenção se voltou a GitHub Actions. Só algumas linhas de YAML e um pouco de documentação e um workflow estava pronto, o segundo já em progresso. O GitHub lida com tudo nativamente, e até roda os workflows de graça contanto que o repositório continuasse público, ou eu não tivesse ultrapassado o limite de minutos do mês.
O motivo de eu nem sempre querer usar Jenkins
Aqui vai um exemplo encurtado de uma Jenkinsfile comum, usando a sintaxe de
pipeline declarativa:
pipeline {
agent { /* ... */ }
options { /* ... */ }
parameters { /* ... */ }
stages {
stage('faz alguma coisa') {
steps {
agoraSimFazAlgumaCoisa
}
}
}
}
As opções de build (options) costumam ocupar múltiplas linhas, bem como a
especificação de agent e os parameters, no caso de uma pipeline
parametrizada. Em cima disso, uma pipeline com um único estágio é algo bem
raro, então replique o estágio no arquivo acima alguma vezes. Como que de
costume, cada estágio terá mais de um step, provavelmente. Ademais, suponha
que a cláusula when será usada para pular alguns passos, e agora você tem
níveis absurdos de indentação e de linhas.
É simplesmente cansativo. Necessário, de vez em quando, mas bem cansativo.
Além disso, quando você estiver instalando e configurando o Jenkins, é bom que você configure e suba agentes de build, sejam dinamicamente provisionados por uma “cloud” ou configurados uma vez e mantidos. Boa sorte gerenciando dependências; só espero que existam imagens Docker suficientes para o seu caso e você não precise subir um certo “repository manager.”
Uma última coisa: você vai precisar de plugins? Espero que sejam mantidos e que não quebrem nas versões mais novas.
GitHub Actions poupa tempo e dinheiro
O Jenkins depende de plugins para sua integração com suítes como GitHub, GitLab, Bitbucket, etc. Você também precisa configurar um webhook a não ser que queira consultar o repositório periodicamente. Tais plataformas foram inteligentes o suficiente para aproveitar a oportunidade criada por empresas implementando CI/CD enquanto hospedam seus repositórios lá, e agora têm suas próprias soluções para fazer essa implementação a mais suave possível.
GitHub Actions é uma dessas soluções. O serviço é gratuito para
repositórios públicos, e você tem 2000 minutos por mês de graça em contas
básicas para usar nos seus repositórios privados. Quer pular o setup do Jenkins,
o plugin, o webhook e a Jenkinsfile, e rodar make para toda pull request?
Ponha isso aqui em .github/workflows/ci.yaml e seja feliz:
on: pull_request
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- run: make
Fluxos de trabalho mais detalhados precisarão de mais linhas, claro, talvez até mais jobs, que são executados em paralelo por padrão a não ser que uma relação de dependência seja explicitada no código. Se você usar runners hospedados por conta (self-hosted runners) nas suas execuções, você não precisa pagar um centavo pelo uso do serviço. Ou seja, você ainda tem a opção de usar sua própria infraestrutura para CI/CD com GitHub Actions.
Já falei bem demais de GitHub Actions. Eu não sou patrocinado por eles, só queria dizer que curto.
Escolhendo projeto, ferramentas, e fluxo de trabalho
Não tem jeito melhor de aprender do que o jeito difícil, e difícil costuma ser pular num oceano quando você mal sabe nadar. Metaforicamente falando, é claro; não faça uma besteira dessas ou você vai se afogar. No meu caso, a metáfora se refere à escolha de um projeto e das ferramentas que vou usar, e à elaboração e subsequente implantação de um fluxo de trabalho que funcione bem para mim.
O projeto que eu escolhi foi a automatização do setup. configuração e deployment de serviços nos meus servidores baseado em uma lista e alguns poucos outros parâmetros. O objetivo é ser capaz de recriar um servidor do zero se necessário.
As ferramentas que escolhi:
- Git para o controle de versão, por razões óbvias.
- Docker para os serviços, usando Compose primariamente.
- Ansible para o setup dos servidores, devido à sua idempotência e porque queria aprender.
- GitHub Actions para os fluxos de trabalho de CI/CD, por razões já listadas.
Por último, o fluxo de trabalho que eu queria era similar ao que obtive com o
Git hook de anos atrás, com duas diferenças chave: mudanças passariam todas por
pull requests, que em torno engatilhariam execuções de CI, rodando o Ansible
em check mode; as execuções de CD são engatilhadas por merges para a master.
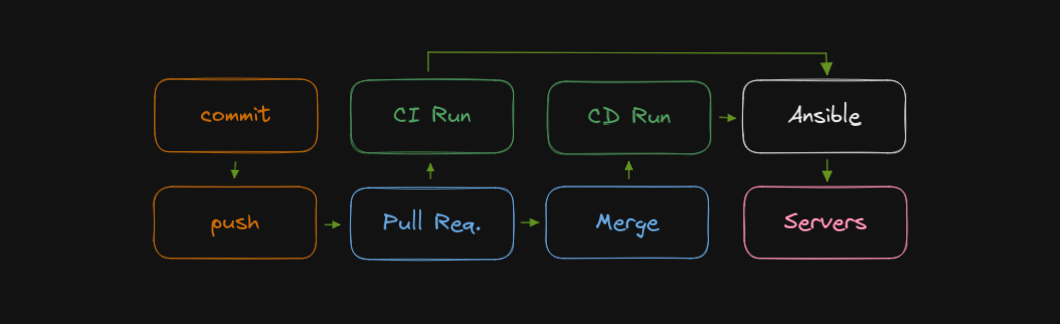
Rascunho do que eu queria, desde git commit até a produção.
Aprendendo Ansible
Ansible me foi apresentado uns anos atrás, mas eu acabei por ignorá-lo completamente. Naquela época eu tinha apenas um servidor pessoal, e o estava usando como servidor de email além de hospedeiro para o meu site e outros serviços simples, como o Syncplay. Não era nem um pouco tentador aprender a configurar tudo de novo do zero, já que isso não aconteceria tão cedo — e foi uma baita trabalheira chegar até lá.
Hoje, anos depois, já não mantenho um servidor de email próprio, e meu site (este) é hospedado no GitHub Pages, me deixando livre para experimentar com os servidores o quanto eu quiser — não tenho mais requisito algum de uptime.
O que eu não sabia antes e que fez Ansible saltar aos meus olhos é o seu objetivo de ser idempotente: convergir a um estado desejado e se manter lá mesmo quando os playbooks são executados repetidas vezes. Um objetivo que vale muito, mas que traz consigo várias dificuldades.
Módulos são uma barreira de entrada, de certa maneira
Uma coisa que existe como uma barreira de entrada no Ansible é o fato das tasks dependerem de módulos, alguns dos quais são embarcados, alguns dos quais são empacotados no “core”, e alguns dos quais são oferecidos em “galaxies” ou seja lá como são chamados os pacotes de terceiros.
Quando se aprende uma linguagem de programação ou markup, tudo de que você precisa é aprender sua sintaxe, seus conceitos centrais, seus membros de primeira classe, e por aí vai. O Ansible usa YAML, e depois de entendidos os conceitos de task, de play, de playbook, de handler, de variable, e de role, o próximo passo é explorar os módulos disponíveis sozinho.
Não quero fazer com isso uma critica severa ao Ansible — sou fã do Ansible,
agora, afinal —, mas tal fato torna mais difícil por de imediato os conceitos
adquiridos em prática. Eu sei o que uma play é, e estou para escrever meu
primeiro playbook, mas… como faço o Ansible garantir a presença de uma linha
em um arquivo? Aprender os conceitos por trás de fato não te leva à conclusão
de que existe um módulo embarcado chamado lineinfile.
É possível usar Ansible sem conhecimento algum de seus módulos? Com certeza! Se
você sabe um pouco de shell script, pode escrever plays que não são em muito
diferentes de um script Bash. Para garantir que um certo arquivo pertença ao
usuário e ao grupo certos, por exemplo, você pode usar o chown e escrever uma
task com o módulo shell:
- name: Garante que /tmp/hippopotamus pertence ao Max
shell: chown max:max /tmp/hippopotamus
Funciona, mas o Ansible não sabe o propósito, as consequências, nem o contexto desta task, por isso só pode rodar o script toda vida às cegas, sem saber se o estado desejado está sendo alcançado. É este, afinal, o sentido de existência da ferramenta: idempotência, convergir para um estado e lá ficar.
O único jeito de dar esta noção, este saber ao Ansible é usando um módulo mais
específico. Neste caso em particular, um que gerencia arquivos e suas
propriedades, em vez de um que roda scripts em shell genéricos. Conseguimos o
que queremos com o módulo file:
- name: Garante que /tmp/hippopotamus pertence ao Max
file:
path: /tmp/hippopotamus
owner: max
group: max
Desta forma, se o arquivo pertence a qualquer outro usuário ou grupo, passará a
pertencer a max:max, e o Ansible reportará que mudanças foram feitas. Se o
arquivo já pertence a max:max, a saída do Ansible mostrará o estado da tarefa
como ok, indicando que não precisou fazer nada.
No exemplo usando shell, o Ansible reportaria sempre que mudanças foram
feitas, já que não conseguiria saber se o script precisou fazer mudanças ou não,
muito menos se realmente o fez, somente que teve que rodar o script. Dá para
forçar o Ansible a não reportar mudanças, ou reportar mudanças baseado em uma
condição, atráves da chave changed_when:
- name: Garante que /tmp/hippopotamus pertence ao Max
shell: chown max:max /tmp/hippopotamus
changed_when: false
Note que o mesmo se aplica ao [módulo command][command], que difere de shell
invocando o comando diretamente, em vez de por meio de uma shell como
/bin/bash. Efetivamente, shell nos permite escrever scripts shell no meio de
nossos playbooks.
Me peguei pesquisando como fazer X no Ansible com relativa frequência no início, já que não tenho grande vontade de decorar palavras numa lista de módulos. O dia em que decidir fazer tal coisa, as plays nos meus repositórios com certeza serão reescritas. No fim, aprender Ansible assemelha-se bastante à jornada de expansão de vocabulário num idioma humano: a prática é necessária.
Como foi por em prática
No final, acabei por escrever múltiplos playbooks, alguns dos quais deixei públicos e alguns dos quais mantive privados já que contêm informações que prefiro manter em segredo no momento. Um resumo:
- Um playbook que realiza o processo de bootstrap dos servidores com configuração essencial;
- Um playbook para sincronizar a lista de usuários no servidor destino;
- Um playbook para garantir que ferramentas essenciais estejam instaladas;
- Um playbook que liga e desliga serviços para cada servidor.
Às vezes precisei “buscar inspiração” em roles disponíveis online. Nunca as quis
usar de verdade, especialmente devido ao fato de fazerem muito mais do que eu
queria, ou não terem suporte para o que eu usava. Foi um aprendizado legal, mas
a melhor coisa que posso afirmar ter vindo disso tudo é saber usar o comando
ansible-doc.
Uma coisa que adoraria abandonar — e espero um dia não ter preguiça demais
para criar meus próprios módulos — é a dependência em tasks que usam o módulo
stat para decidir pular passos futuros. Cláusulas condicionais, das quais isto
é um equivalente, não são bonitas em Ansible, mesmo que funcionem e nos ajudem a
obter a gloriosa idempotência. É uma “idempotência barata”, de certa maneira.
GitOps, o que é e por quê
Consigo escrever bastante sobre as ferramentas que usei e a forma como as usei, mas este artigo já se estendeu o suficiente. Mais artigos virão explicando e / ou ensinando a fazer isso e aquilo com as ferramentas com as quais me familiarizei ao longo do tempo.
Um desígnio que me motiva bastante ultimamente é o que a WeaveWorks decidiu chamar de GitOps; um fluxo de trabalho — filosofia, diriam alguns — resumido por “um repositório Git deveria ser a única fonte da verdade.” Há várias possíveis definições, mas esta deve servir:
Um repositório Git é a única fonte da verdade para o estado desejado do sistema inteiro. Este estado desejado é descrito de forma declarativa, enquanto mecanismos de convergência são implantados para garantir que ele é atingido.
Em outras palavras, mudanças na configuração são relacionadas 1:1 a pull requests em um fluxo de trabalho GitOps.
Entenda por configuração o estado de um sistema, não arquivos de configuração e afins usados por software para alterar seu comportamento. Exclua daí dados persistentes produzidos pelo uso do sistema — que, com sorte, não afetam o seu comportamento general, pois determinismo em software é bem imprevisível, ou ao menos dificilmente gerenciável.
Apesar deste jeito de fazer deployment ter seus próprios defeitos ou em algum momento sofrer um declínio de popularidade por qualquer razão, ele oferece agilidade relativa, seguindo fielmente a cultura DevOps e metodologias ágeis de desenvolvimento.
Como eu acho que o alcancei no meu setup
A WeaveWorks criou o termo descrevendo um fluxo de trabalho que circula clusters
Kubernetes. Faz bastante sentido falar de descrições declarativas do
estado almejado quando objetos Kubernetes têm todos o que chamamos de manifesto
YAML. Algumas propriedades só existem quando o objeto em si está “no ar”, como
aquelas dentro de {.status}, mas tirando isso os objetos em si são
praticamente idênticos aos manifestos que os geraram.
É possível desginar um fluxo de trabalho como GitOps quando ele não envolve algo como Kubernetes? Pensando um pouco e com uma mente aberta, contanto que o estado desejado seja declarado em vez de listarmos instruções a serem executadas — há controvérsias em dizer que o Ansible satisfaz essa condição devido à relevância da ordem das tasks — e hajam mecanismos de convergência, dá para dizer que sim.
Digamos que apesar da ordem de execução das tarefas ser de grande importância ao
Ansible, e a ausência de um esquema de resolução de dependências — como que o
Ansible saberia que o pacote certbot precisa estar instalado para podermos
usar o comando certbot? —, playbooks são uma especificação declarativa do
estado desejado para nossos hosts. Então estaríamos certos em dizer que um
fluxo de trabalho que usa Ansible como mecanismo de convergência constitui
GitOps.
Eu acredito que dá para ignorar as partes do estado do sistema não gerenciadas
pelo Ansible, já que há “partes não contempladas” também em fluxos de trabalho
envolvendo Kubernetes (pense em autenticação ou PersistentVolumes). Sejamos
felizes em dizer que tudo de que precisamos para mudar o sistema é um git commit e contentes na simplicidade dos nossos setups de CI/CD.