Experiences with CI/CD and DevOps
Practicing DevOps with pen and paper
WARNING: This became such a lengthy article despite the relative lack of detail that it forced me to include a table of contents. Hopefully it isn’t too tiresome to read through, and whoever reads it can jump to whatever topic might interest them.
The goal of this blogpost is to give the reader an overview of what it was like for me to get accustomed to and implement some continuous integration (CI) and continuous deployment (CD) solutions to my own personal projects. It was and is still being a bumpy ride, but it’s more gratifying than I thought it would be when I first started.
My general attitude towards CI/CD services, programs, platforms, and the like was that they were “simply not for me,” and something only big projects or companies, led by a highly qualified work force, would really need and benefit from.
That position has, of course, changed since then as working with improving the software development lifecycle first hand made me realize just how much sense it all makes. I now crave to bring automated tests, code reviews, constant pull requests, and automated deployment to all of my personal projects. It is a great way to define and guarantee a standard of quality.
Humble beginnings: Git hooks & GNU Make
The first software development pipeline — if you can even call it that — I
devised was a combination of Git, Bash, and GNU Make, the latter gluing together
programs like Hugo and rsync. Its goal was to automate deploying my
personal website.
Git was used to version the source files, GNU Make was used to simplify the
build and deployment processes into make and make deploy, Hugo was used to
turn Markdown + templates into HTML/CSS, and rsync was used to copy the
generated static pages to the web root — /var/www.
To turn a git push into the only command necessary to trigger a build and
deploy the new content, a post-receive Git hook was set up on a
bare repository hosted on the VPS that served the website. The hook was nothing
more than a shell script, which was roughly:
cd /path/to/the/worktree # go to a clone of the repo
git fetch origin # fetch the new commits
git reset --hard origin/master # sync up with the master branch
make && make deploy # build and deploy pages
As long as all permissions were properly set and dependencies were met, this
meant all I realistically had to do to update the pages on my website was edit
the files locally, create new commits, and push them to the remote. If any
errors occurred, I was able to see them in the output of git push, since it
displays the output of Git hooks as they’re executed.
Why this lacks Continuous Integration
As happy as I was with my new discovery (namely Git hooks) and my setup, looking back on it I cannot say it featured CI. Before my reasons for thinking so are outlined, the following is the definition of Continuous Integration given by Atlassian:
Continuous Integration (CI) is the practice of automating the integration of code changes from multiple contributors into a single software project. It’s a primary DevOps best practice, allowing developers to frequently merge code changes into a central repository where builds and tests then run.
I believe CI can be achieved even when there’s a single contributor, but if you disagree with me, add that to the following list of reasons why I don’t think what I was up to was continous integration.
Reason #1: There was always a single branch — master — so changes
being tested had already been integrated.
The point of CI is to test and review changes before they make their way to their target branch. That’s why a suite like GitHub, GitLab, Bitbucket, and so on is so useful: they all materialize the proposal of changes into pull (or merge) requests. These requests can be denied, accepted, reviewed, etc., and the coolest thing is that when they’re created or changes are made to them, these suites can let us know so programmatically through webhooks, and even handle the events themselves natively.
In my case, there were no pull requests: commits were added to master and
pushed directly upstream, no questions asked.
Reason #2: The only test being performed is deployment.
There’s no automated testing of any kind, not even to see if the static pages can still be generated. I can even recall some times I broke the static page generation by experimenting with Hugo’s layout capabilities — the version of Hugo installed on my machine and on the remote host were different.
The lack of a reproducible environment for testing (and obviously the tests themselves) meant the risk of breaking production was taken every time a deployment was performed.
Reason #3: Changes didn’t undergo any review processes.
For many people, code review isn’t necessarily within the scope of continous integration, but in my humble opinion, it is central to it. If CI is about controlling or ensuring a degree of quality before any changes are merged into stable branches, reviews are perfectly aligned with it, and sit in the way of integration.
I said before that I believe CI can be achieved even when there’s a single contributor, so why do I bring up this point? That’s because I simply didn’t review my own changes. I tested them locally, sure, but I didn’t review them with “impartial eyes” after development. The lack of any manner of review process, to me, makes it unfit for the moniker of Continuous Integration.
How it might have Continuous Deployment
If you squint hard enough, or if you’re permissive in the coupling of CI and CD, the Git hook setup did feature continuous deployment. Once more, we’ll start with a definition. This time, it comes from TechTarget:
Continuous Deployment (CD) is a strategy for software releases wherein any code commit that passes the automated testing phase is automatically released into the production environment, making changes that are visible to the software’s users.
Commits that reached the master branch, used for production in our situation,
would automatically make their way to production — the website as it was
served by my VPS. In that sense, this is an example of continuous deployment,
but if there’s no CI, can there be CD? Is the “automated testing phase”
necessary to constitute continuous deployment?
Myself, I’d say no. While both are fundamental premises for DevOps, setting up CI and CD is often done separately. Were the two truly codependent, we’d probably have a single term for the entire process that specifically addressed both practices.
The road to proper CI/CD
My eyes were opened to CI/CD when I started working. Up until then I didn’t really know what the terms meant, if I’d heard them at all. To me, CI was the latter part of the name for Travis CI, a tool that ran some automated builds on the XMonad repository, and CD was an optical media format.
Then I started working and came into contact with Jenkins. It was
presented to me as the CI/CD tool of choice for most people, and I can tell why.
It feels incredibly hacked together, however, and very resource hungry. Despite
that, with gleeming eyes gazing at a newfound appreciation for software
development, I vowed to write some Jenkinsfiles for my own purposes.
Soon after setting up my first couple of repositories and reading through Jenkins’ documentation, thinking “man, this took some effort to set up, but it’ll pay off,” my attention shifted to GitHub Actions. With just a few lines of YAML and reading through documentation, a workflow was set up, and work could start on another. GitHub would handle everything natively, and run it all for free as long as the repository remained public or I didn’t go over my minutes-per-month limit.
Why I don’t like using Jenkins unless I have to
This is a shortened example of an average Jenkinsfile using the declarative
pipeline syntax:
pipeline {
agent { /* ... */ }
options { /* ... */ }
parameters { /* ... */ }
stages {
stage('Do something') {
steps {
actuallyDoSomething
}
}
}
}
The options usually span multiple lines, as does the agent specification and the
parameters, if this is a parameterized pipeline. On top of that, a pipeline with
a single stage is a rare thing, so replicate the one stage in the file above,
keeping in mind it’ll definitely have more than one step. Moreover, suppose the
when clause will be made necessary for subsequent stages, and you have
yourself unnecessary levels of indentation and line numbers.
It’s just so tiresome. Sometimes necessary, I’ll give Jenkins that, but so tiresome.
Finally, remember that when setting up Jenkins you’ll probably have to set up Jenkins agents, be it dynamically provisioned through a “cloud” or set up once and maintained. Good luck managing dependencies, I just hope there are enough Docker images for what you need and you don’t have to spin up a certain repository manager.
One last thing: are you going to need plugins? Here’s hoping they’re well maintained and don’t break in newer versions.
GitHub Actions just saves time and money
Jenkins relies on plugins for its integration with suites like GitHub, GitLab, Bitbucket, etc. You’ll also have to set up webhooks unless you like polling for updates periodically. All these platforms are smart enough to cash in on companies implementing CI/CD while hosting their repositories there, and provide their own solutions to make the integration painless, or just unnecessary.
GitHub Actions is an example of such a service. It’s free for
public repositories as of the time of this writing, and you get 2000 minutes per
month for free for private repositories on a basic account. Want to skip setting
up Jenkins, the plugin, the webhook, the Jenkinsfile, and run make for every
pull request? This is enough:
on: pull_request
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- run: make
More intricate workflows will necessitate more lines, of course, perhaps even more jobs, which are run in parallel unless inter-job dependencies are explicitly stated. On top of that, you don’t have to pay a dime if you use self-hosted runners for your runs, so you still have the option to set up your own infrastructure for CI/CD while using GitHub Actions.
That’s enough praise for GitHub Actions. I’m not sponsored by them, but the point is I quite like it.
Picking a project, tools, and workflow
There is no better way to learn than the hard way, and the hard way usually means plunging into open sea when you barely know how to swim. Metaphorically, of course; don’t go doing that or you will most likely drown. In my situation, that means picking the tools I want to work with after some consideration, picking a project I think would benefit from them, and devising and implementing a workflow that works for me.
The project chosen was automating server setup, configuration and deployment of services based on a list and few other parameters. The goal is to be able to almost entirely recreate a server from scratch if need be.
The tools picked were:
- Git for version control, for obvious reasons.
- Docker for the services, primarily using Compose files.
- Ansible for server setup, due to idempotency and, well, because I wanted to pick it up.
- GitHub Actions for the CI/CD workflows, for reasons already outlined.
Finally, the workflow I wanted was similar to what I achieved with the Git hook
of years prior, with a couple of key differences: changes would all have to go
through pull requests, which in turn trigger CI runs, that run Ansible in
check mode; finally, the CD runs are triggered by merges into master.
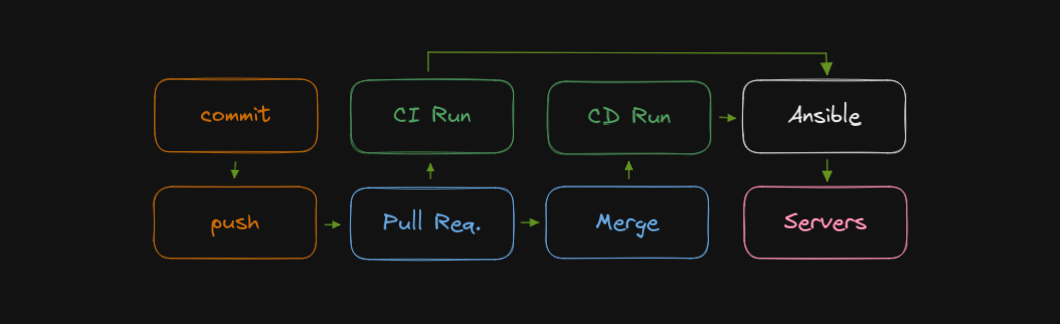
Rough sketch of what I wanted, from git commit to production.
Picking up Ansible
Ansible was presented to me at one point a few years ago, but I shrugged it off completely. At the time I had only one VPS, and I was using it as a mail server on top of hosting my website and other simple services such as Syncplay. It was hardly tempting to learn how to set it all up again from scratch, as that wasn’t going to happen anytime soon.
Now, years later, I’m no longer maintaining the cumbersome mail server setup, and my website is hosted on GitHub Pages, so I’m free to experiment with the VPSes as much as I want — none of them come with an uptime requirement.
The thing I didn’t know back then that really made Ansible stand out is its goal to be idempotent: to converge into a desired state and remain there even when the playbooks are applied again and again. A worthy goal, but also one that would bring with it some difficulties.
Modules are a barrier to entry, in a way
One thing that is a bit of a barrier to entry in Ansible is the fact that tasks rely on Ansible modules, some of which are built-in, some of which are provided in the “core”, some of which are provided by third party “galaxies” or whatever they’re called.
When it comes to picking up a programming or markup language, all you really need to learn is the general syntax, the core concepts, the first class members, and so on. Ansible uses YAML, and after understanding the notion of a task, a play, a playbook, a handler, a variable, a role, you’re sort of left on your own to explore available modules.
This is not meant as a harsh critique of Ansible — I quite like it, after all
— but it does make it feel more difficult to immediately convert the concepts
you just learned into practice. I know what a play is, and I’m about to write
my first playbook, but… how do I make Ansible ensure some line is present in a
file? In reading about those concepts, you’re not even once shown there is a
built-in module called lineinfile.
Can you use Ansible without any knowledge of its available modules? Of course!
If you know some shell scripting, you can write plays with tasks that are no
different from any old Bash script. To ensure some file has the right ownership,
for example, you can use the chown program, and write a task using the shell
module:
- name: Ensure /tmp/hippopotamus is owned by Max
shell: chown max:max /tmp/hippopotamus
It works, but the disadvantage of such a task is that Ansible is unaware of its purpose, consequences, or context, and so it can only run the script every time without knowing whether or not the desired state is achieved. That is, after all, the whole point of Ansible: idempotency, i.e. to converge to a desired state and remain there no matter how many times the tasks are executed.
The only way to give Ansible this sort of awareness is by using a more specific
module. In this case one that handles generic operations on files, rather than
the one that runs generic shell scripts. We can achieve what we want with the
built-in file module:
- name: Ensure /tmp/hippopotamus is owned by Max
file:
path: /tmp/hippopotamus
owner: max
group: max
This way, if the file is owned by someone else, its ownership will be changed to
max:max, and Ansible will report changes were made. If the file is already
owned by max:max, Ansible will report the task’s status as ok (no changes
were necessary).
With the shell example, Ansible would always report changes were made, since
it can’t know whether the script had to make changes or not, nor if it actually
did, only that it had to run the script. You can force Ansible not to report
changes, or to report changes on the task based on a condition, through the
changed_when key:
- name: Ensure /tmp/hippopotamus is owned by Max
shell: chown max:max /tmp/hippopotamus
changed_when: false
Note that the same is true for the built-in command module,,
which differs from shell in the sense that it invokes the command directly,
while shell forwards its contents to something like /bin/bash. Effectively,
shell lets us write scripts in our playbooks.
All in all, I find myself often looking up how to do X in Ansible, since I can’t be bothered to read through more than a few pages listing modules available for use. The day I decide to do so, the plays in my repositories will likely all be rewritten from scratch. In the end, learning Ansible is akin to expanding one’s vocabulary in a different human language: practice is pretty much necessary.
What it was like to put into practice
In the end, I wrote multiple playbooks, some of which were made public and some of which remain private since they contain some information I’d rather keep private for the time being. A brief summary:
- A playbook to bootstrap hosts with essential configuration;
- A playbook to sync users with the target host;
- A playbook to ensure some essential tools are installed;
- A playbook to bring up or down services as specified for each host.
At times I had to draw inspiration from Ansible roles available online. I never
truly wanted to use them, especially since they either did much more than I
wanted, or didn’t have support for specifically what I wanted. It was quite the
learning experience, but the best thing I can say came out of it was learning
how to use the ansible-doc command.
One thing I wish could change — and I hope to one day stop being too lazy to
create my own Ansible modules — is my reliance on tasks that use the stat
module being used to decide whether to skip further tasks. If statements, which
this is an equivalent of, are not pretty in Ansible, even if they get the job
done and allow us to achieve idempotency. It’s “cheap idempotency,” if you will.
GitOps, what it is and why
There’s plenty I could write on the other tools I chose to use and the way I used them, but this article has extended itself enough. More articles are to come explaining and / or teaching how to do this or that with the tools I’ve managed to familiarize myself with over time.
What I can say has been a bit of a goal and motivation for me is what WeaveWorks decided to call GitOps; a workflow — philosophy, some would say — summarized by “a Git repository should be the single source of truth.” There are plenty of candidates for a proper definition, but this should suffice:
A Git repository is the single source of truth for the desired state of the whole system. This desired state is described declaratively, while convergence mechanisms are put in place to ensure the desired state is reached.
In other words, changes in configuration equate to pull requests in a GitOps workflow.
Take configuration here to mean the state of a system, not just configuration files and the like, that different pieces of software use to alter their behavior. Exclude from this whatever persistent data is produced by the use of the system — which hopefully won’t actually affect its general behavior, as determinism makes software a little unpredictable, or at the very least unmanageable.
While this approach to deployment might come with its own shortcomings or eventually fall out of fashion for one reason or another, it does provide relative agility, going hand in hand with DevOps culture and agile development methodologies.
How I think I achieved it with my current setup
WeaveWorks coined the term in describing a workflow surrounding
Kubernetes. It makes a lot of sense to speak of declarative descriptions
of the intended state of the system, considering Kubernetes objects all have
what we call YAML manifests to them. Though there are certain properties under
{.status} that only exist when the object itself is up and “running,” objects
are for the most part equal to the YAML manifests that generated them.
Without something like Kubernetes, it is really possible to award a workflow the name GitOps? If you think about it, and obviously keep an open mind for this, as long as you can declare the state of your “target” instead of outlining a series of instructions to perform — it is debatable whether Ansible meets the criteria, considering order is more than relevant — and you have convergence mechanisms put in place, you should be.
Let’s say that despite Ansible’s heavy reliance on the order of the changes it
needs to perform, and the lack of seamless dependency management — how would
Ansible know that certbot, the package, needs to be installed for cerbot,
the tool, to be used? — is no reason why we can’t call playbooks a declarative
specification for how we want our hosts to be. In that case, it is perfectly
fine to say that a workflow that uses Ansible for converging to a desired state
constitutes GitOps.
I believe we can leave out the parts of the system’s state that aren’t managed
by Ansible, since these “unmanaged parts” are also part of workflows surrounding
Kubernetes (think of the contents of PersistentVolume objects, or
authentication with the cluster). Let’s just be happy that we can say a git commit is the only change we truly need, and rejoice in the simplicity of our
CI/CD setups.